
С моей точки зрения, Erlang - один из наиболее продуманных языков программирования. Его создатели выбирали каждую деталь и особенность реализации так, чтобы сделать его идеальным для решения вполне конкретных телекоммуникационных задач, с которыми они сталкивались в 80-90-х годах. Во многом из-за этого он так и не стал универсальным языком программирования как C++, Python и другие, а так и остался спустя многие годы специализированным инструментом. Сегодня спрос и предложение на специалистов по Erlang на рынке труда относительно малы, что для большинства проектов является основным аргументом против Erlang, хотя порой они и сталкиваются с задачами, где он запросто бы стал тем самым "идеальным инструментом". В этой статье я хотел бы обсудить, в каких именно ситуациях применительно к интернет-проектам использование Erlang оправдано и почему. Но начать придется издалека - с того, чем же он так уникален.
Что такое Erlang?
Под словом Erlang обычно подразумевают совокупность сразу нескольких компонентов:
- Сам одноименный язык программирования - по сути синтаксис и идеологию;
- ERTS(Erlang Run-Time System) - реализация всех низкоуровневых абстракций на C. Подробнее о них ниже.
- BEAM(Bogdans' Erlang Abstract Machine) - стандартная реализация виртуальной машины, с помощью которой обычно исполняются программы на Erlang после компиляции в байт-код (она очень эффективна; хотя компиляция Erlang в нативный код и возможна, оно того чаще всего не стоит). BEAM используется по-умолчанию в основных дистрибутивах Linux и других операционных системах. Когда говорят "виртуальная машина Erlang" обычно подразумевается совокупность ERTS и BEAM.
- OTP(Open Telecom Platform) - набор качественно реализованных высокоуровневых абстракций, использование которых стало почти стандартом де-факто в мире Erlang, так как оно позволяет не изобретать велосипеды и избегать типичных ошибок при реализации типичных же паттернов. Немного забегая вперед, приведу несколько примеров: gen_server (просто процесс, который принимает какие-то запросы и как-то на них реагирует), gen_fsm (конечный автомат), supervisor (мониторинг других процессов).
Ключевые особенности
- Параллельное программирование(concurrent programming) - программы на Erlang состоят из независимых задач, которые могут выполняться параллельно, что на практике дает свободу виртуальной машине планировать их выполнение наиболее эффективным образом с учетом доступных системных ресурсов.
- Процессная модель(process model) - единицей параллельного выполнения в Erlang является процесс, который технически представляет собой лишь часть потока исполнения (thread) операционной системы и обладает нижеизложенными свойствами, которые обеспечивает их реализация в ERTS:
- Параллельность(concurrency) - каждый процесс выполняет свою часть кода вне зависимости от других процессов, со своим темпом.
- Изоляция процессов(process isolation) - в отличии от потоков исполнения в операционных системах и других языках программирования, между процессами Erlang'а нет общей памяти. Помимо этого сбой в одном из процессов напрямую не влияет на другие процессы в системе. Именно по-этому они называются процессами, так как в этом ключе скорее похожи на полноценные процессы операционной системы.
- Низкое потребление ресурсов (low resource consumption) - так как процессы Erlang являются лишь абстракцией внутри потока исполнения операционной системы, используют зачастую меньше килобайта оперативной памяти и требует минимальных вычислительных ресурсов, то один сервер может при необходимости иметь сотни тысяч и даже миллионы запущенных процессов (теоретически возможный максимум - 268435456, хотя по-умолчанию стоит ограничение в 32768 процессов). Для сравнения: суммарное количество потоков выполнения на сервере обычно измеряется сотнями и редко превышает тысячу.
- Слабая связанность (loose coupling) - процессы общаются друг с другом посредством асинхронного обмена сообщениями (message passing), для чего часть памяти каждого процесса выделяется под "почтовый ящик". При отправке сообщения в списке входящих сообщений процесса-получателя создается копия сообщения, составленного в процессе-отправителе. При этом протокол отправки сообщений между процессами скрыт от разработчика и не зависит от того, находится ли получатель в той же виртуальной машине или в удаленной (на другом сервере), что позволяет легко и практически прозрачно распределять приложения по многим физическим серверам (горизонтальное масштабирование, scale out).
- Дерево ответственности(responsibility tree) - создаваемые внутри системы процессы образуют иерархию, где родители несут ответственность за потомков. В упомянутом чуть выше примере сбой одного из процессов вызывает его завершение и рассылку уведомлений связанным процессам-соседям по иерархии (с информацией о том, где и почему произошел сбой), на которые они могут как-то реагировать. Типичных сценария реагирования два: также завершить работу и разослать аналогичные уведомления, вызывая цепную реакцию (такие процессы называют исполнителями, worker), либо на основе уведомления принять какое-то действие, например попытаться заново запустить часть дерева процессов, аналогичную остановленной (такие называют надсмотрщиками, supervisor). Использование этого механизма позволяет приложению добиться отказоустойчивости.
- Ссылочная прозрачность(referential transparency) - как только переменная получила какое-то значение его уже нельзя изменить (single assignment), для нового значения нужно заводить новую переменную. На первый взгляд выглядит полным бредом, но именно эту цену нужно заплатить для гарантии того, что какая-то другая часть кода втихаря не "испортит" значение. Плюс отсутствие изменений в структурах данных в памяти дает большую свободу для применения различных оптимизаций компилятору, сборщику мусора и планировщику процессов.
- Планировщик процессов(scheduler) - виртуальная машина Erlang с точки зрения операционной системы выглядит как один процесс с несколькими потоками исполнения (threads), каждый из которых имеет собственный планировщик, управляющий группой Erlang-процессов. Процессы могут прозрачно перемещаться из одного потока в другой для балансировки нагрузки. Помимо этого планировщик берет на себя управление вводом-выводом, которые на низком уровне реализованы в неблокирующей, основанной на событиях, манере с использованием epoll или аналогов, но для конечного разработчика представляется в упрощенном виде.
- Сборщик мусора в памяти(garbage collector) - в отличии от других виртуальных машин (в частности JVM) сборка мусора в Erlang не влечет за собой значимых задержек в работе приложений, так как благодаря изоляции процессов для сборки мусора они останавливаются по очереди, пока все остальные продолжают работать. Обычно область памяти выделенная под один процесс очень невелика (для сравнения: под новый процесс в Erlang выделяется около 1 килобайта, под новый поток исполнения в Java - более 512 килобайт в зависимости от реализации), так что сборка мусора для каждого процесса не занимает много времени. Планировщик может определить какие процессы нужно пропустить при очередной сборке мусора, если они не исполнялись с момента предыдущей сборки. Если процесс создается для выполнения кратковременной задачи, то он может успеть сделать свое дело и завершиться без единой сборки мусора, полностью освободив свою память по окончании работы.
- Функциональное программирование (functional programming) - если рассмотреть один Erlang-процесс внутри, отбросив его связь с внешним миром (обмен сообщениями), то можно увидеть программу, полностью соответствующую функциональной парадигме: алгоритмы выражаются в виде вызовов функций, которые, в свою очередь, являются единицами данных наравне с числами и сложными структурами. На практике же это означает другой стиль программирования и используемые абстракции (рекурсия вместо циклов, поведения вместо интерфейсов и т.п.), по сравнению с более распространенными объектно-ориентированными языками; подробно это будет интересно лишь программистам, так что оставим это для другой статьи про Erlang.
- Доступно три механизма хранения данных вне памяти процессов:
- ETS(erlang term storage) - очень похожий на хранилище пар ключ-значение механизм, работающий в оперативной памяти самой виртуальной машины и доступный всем или части её процессов (есть ограничения доступа). Данные хранятся в пространствах имен (таблицы без жесткой структуры), а доступ осуществляется по ключу, который являются частью значения (обычно первым элементом в хранящейся структуре данных).
- DETS (disk erlang term storage) - предоставляется аналогичный ETS интерфейс и формат хранения данных, с той лишь разницей, что данные хранятся в файлах на диске, а не в памяти виртуальной машины. При использовании нетвердотельных дисков операции поиска данных значительно медленнее аналогов из модуля ETS.
- Mnesia - полноценная СУБД на основе ETS/DETS, с поддержкой атомарных транзакций (atomic transactions), репликации (replication) и партиционирования (sharding). Позволяет абстрагироваться от физического расположения данных, осуществлять поиск/выборки данных в реальном времени, а также вносить изменения в конфигурацию и схему данных без перезапуска.
- Горячее обновление кода(hot code loading) - виртуальная машина может держать в памяти и параллельно выполнять две версии одного и того же кода (единицей измерения здесь является модуль, то есть один скомпилированный файл исходного кода), процесс переключается со старого кода на новый при выполнении внешнего вызова к одной из его функций (что в целом полностью в руках разработчика). Эта возможность позволяет полностью избежать недоступности приложения при обновлениях, что очень важно для всех приложений, работающих в реальном времени, к которым также относятся все сайты и интернет-сервисы.
Применение на практике
Телекоммуникации и Интернет на сегодняшний день хоть и являются совершенно разными областями информационных технологий, но все же глобальная цель у них общая: позволять людям легко общаться удаленно. Предлагаю вернуться к изначальной теме статьи: в каких конкретно ситуациях Erlang, вместе со своими изложенными выше особенностями и ограничениями, может оказаться уместным решением задач интернет-проекта? Примеры могут показаться субъективными, так что с удовольствием готов обсудить их и другие ситуации в комментариях.
Входящие пользовательские соединения
Еще в далеком 2002 году в сети часто мелькал сравнительный бенчмарк Apache(C) и Yaws(Erlang) по обработке HTTP-запросов, где Yaws представлялся "победителем" с огромным отрывом. С тех пор конечно же многое поменялось, появился стремительно набирающий обороты nginx и "популярные в узких кругах" решения вроде node.js или Tornado.
Но Erlang тоже не стоит на месте. Благодаря целенаправленной работе по оптимизации ERTS в целом и планировщика процессов в частности, современные реализации HTTP-серверов на Erlang по-прежнему легко дают фору более распространенным решениям.
В последние годы появляется все больше интернет-проектов, использующие постоянные соединения (websocket, long polling, etc.) между браузером и HTTP-сервером для обновления страниц сайта в реальном времени. Здесь также Erlang легко справляется с задачей, так как для поддержания постоянного соединения обычно используется лишь 1 Erlang-процесс (хотя иногда 2), которые, как уже упоминалось, потребляют минимум оперативной памяти и вычислительных ресурсов. Как следствие, HTTP-сервер на Erlang способен поддерживать очень постоянное соединение с онлайн пользователями, даже если их количество измеряется десятками тысяч.
Хочется отметить, что в этом примере речь идет именно об обработке соединений с пользователями, то есть внутри HTTP-сервера минимум логики, он просто "разбирает" запрос и, вероятно, передает его дальше внутрь системы через брокер сообщений или напрямую внутренним сервисам. К вопросу с сколько-либо сложной бизнес-логикой вернемся чуть позже.
Отдача статики
Для отдачи статики в Erlang часто используют тот же системный вызов sendfile, что и в nginx. Но на практике ситуация здесь неоднозначна:
- прямой доступ к sendfile через встроенные вызовы (BIF, Built-In Functions) появился в Erlang только в самом последнем на сегодняшний день релизе - R15B;
- раньше использовалась обертка с использованием нативных функций (NIF, native implemented functions) или просто чтение файла, что работало не очень хорошо.
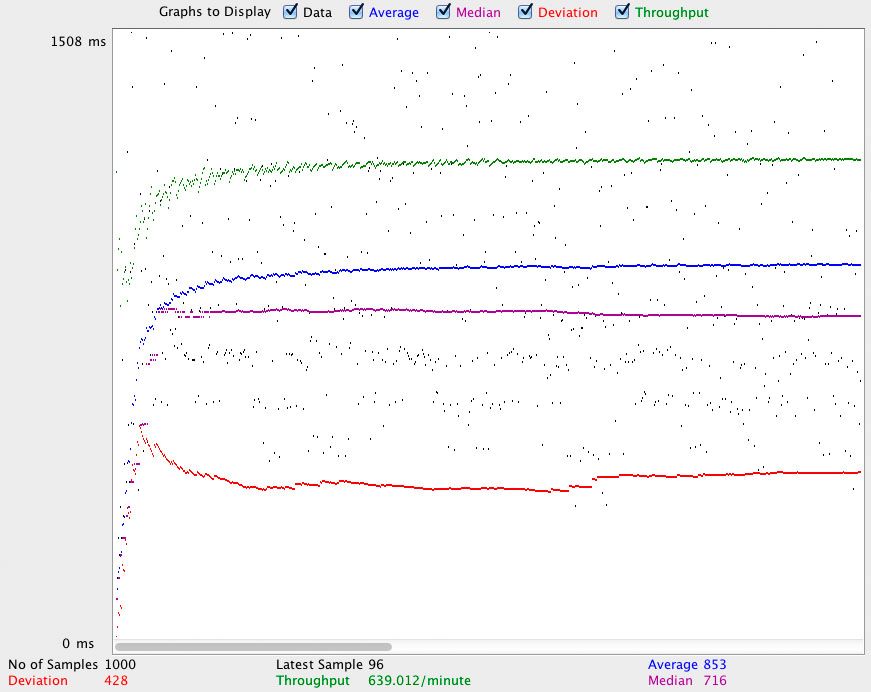
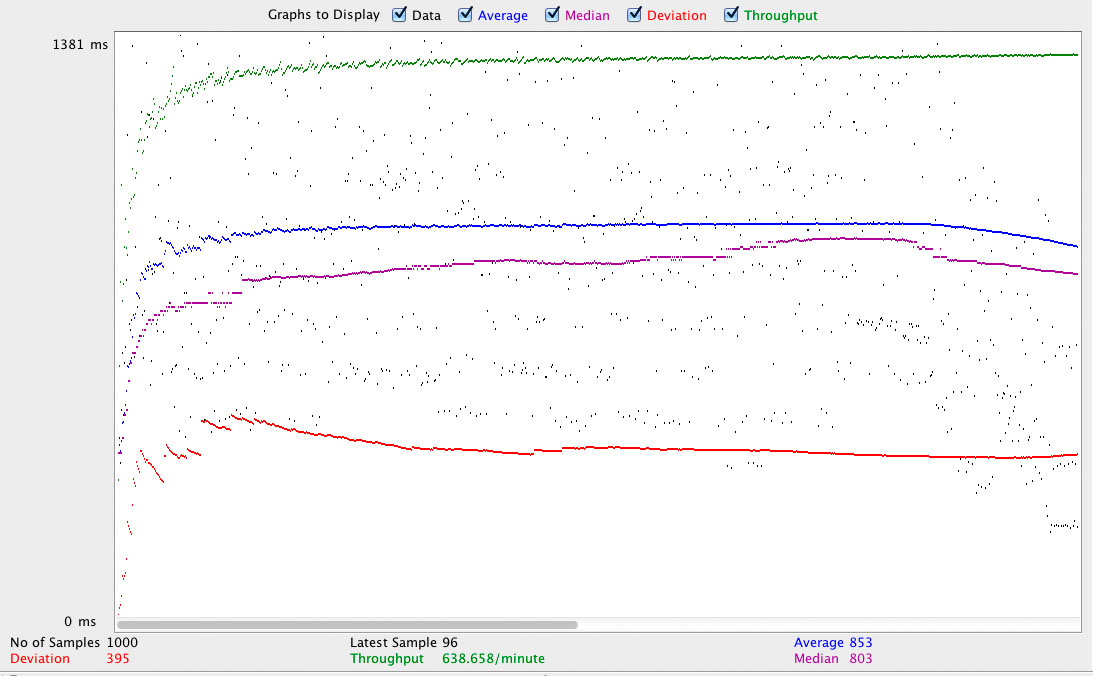
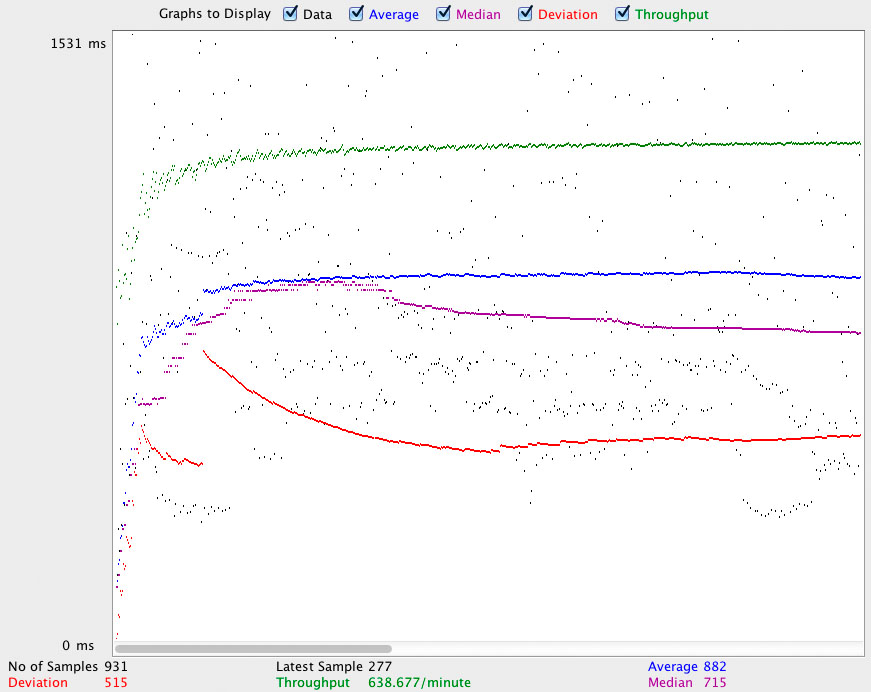
1.1Мб картинка в 10 потоков (нехитрая математика говорит о том, что все упираются в сеть):
- Cowboy без sendfile: 853мс. в среднем, 639 запросов в минуту, отклонение 428мс.
- Cowboy с sendfile: 853мс. в среднем, 639 запросов в минуту, отклонение 395мс.
- Nginx: 882мс. в среднем, 638 запросов в минуту, отклонение 515мс.
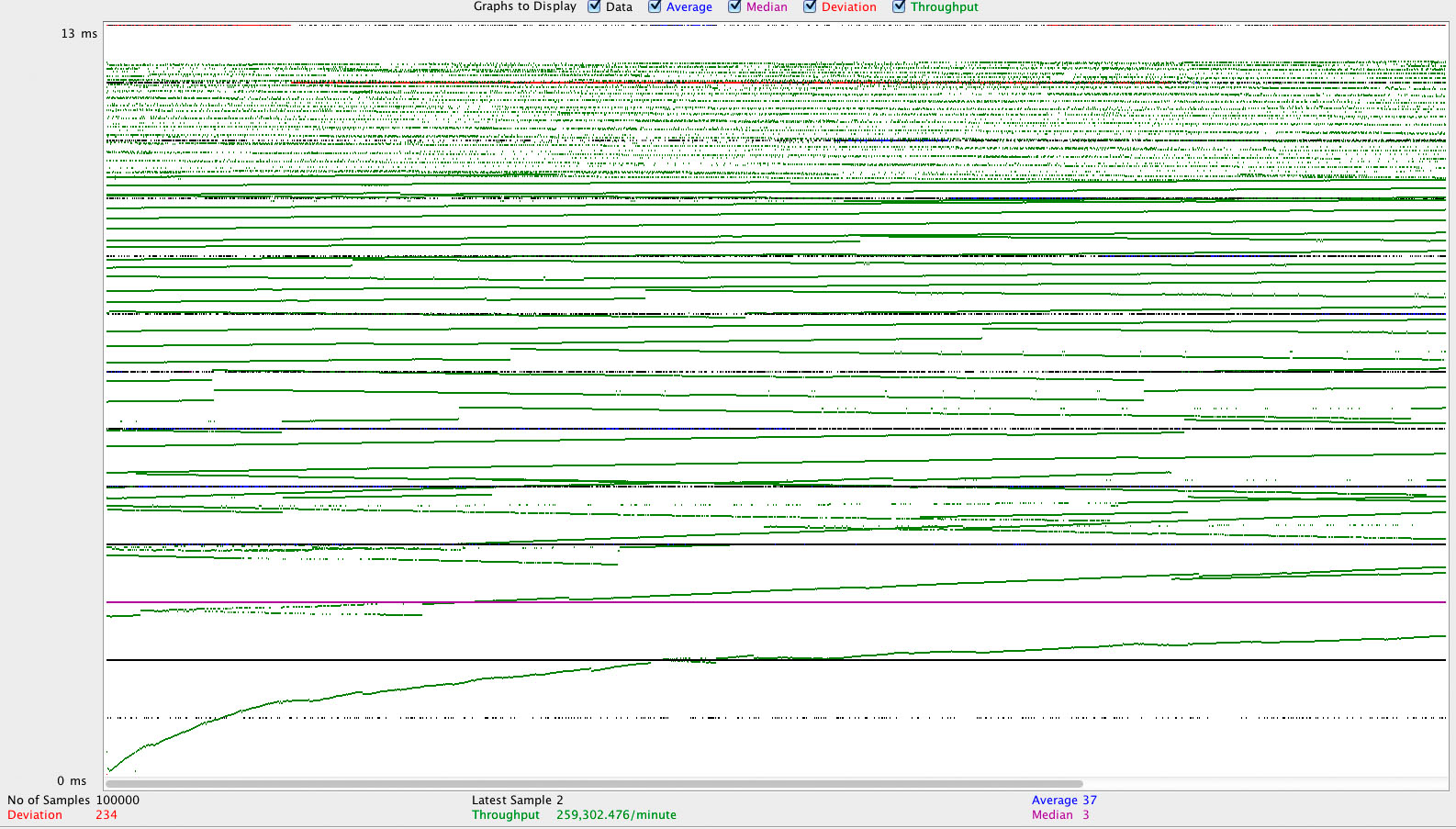
112б текстовый файл в 1000 потоков:
- Cowboy без sendfile: 37мс. в среднем (но медиана - 3мс., то есть небольшая часть запросов сильно тормозит, а с остальной все нормально), 259 тыс. запросов в минуту, отклонение 234мс.
- Cowboy с sendfile: 17 мс. в среднем, 267 тыс. запросов в минуту, отклонение 27мс.
- Nginx: 2мс. в среднем, 315 тыс. запросов в минуту, отклонение 3мс.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Не претендуя на хоть на какую-либо точность и применимость в боевых условиях, эти цифры и графики показывают, что в деле отдачи статики nginx хоть и по-прежнему лидер, но в не-экстремальных ситуациях особой разницы можно и не заметить. Хотя при использовании решений на Erlang определенно можно начать "скучать" по нестандартным конфигурациям nginx с какой-нибудь компрессией на лету, rewrite'ами и пр. В любом случае, для отдачи статики в сколько-либо серьезных интернет-проектов рекомендую пользоваться услугами CDN.
Балансировка нагрузки
Откровенно говоря, я не слышал о каком-либо проекте на Erlang для балансировки HTTP и/или TCP запросов, хотя бы отдаленно сравнимом по возможностям, надежности и производительности с HAProxy и "железными" решениями.
Хотя по мне так сами свойства Erlang прекрасно подходят для решения этой задачи, но те проекты, на которые я натыкался (пример), выглядят просто как "поделки" по сравнению с проверенными временем решениями.
В любом случае HTTP/TCP балансировщик нагрузки на Erlang - отличная тема для нового opensource проекта, если вдруг кому-то нечем заняться в свободное время :)
Брокер сообщений
В статье про RabbitMQ я уже подробно рассказывал о том, как Erlang вписывается в роль брокера сообщений, то есть посредника между различными компонентами системы, обеспечивающего их слабую связанность путем обмена сообщениями.
В дополнение хочется сказать, что хоть изобретать велосипед и редко когда оказывается хорошей затеей, Erlang отлично подошел бы и для реализации собственной схемы обмена сообщениями внутри системы, например без использования централизованного брокера, как это в итоге получается с использованием RabbitMQ или аналогов.
Бизнес-логика
Этот аспект является практически уникальным от проекта к проекту, так что здесь придется ограничиться лишь какими-то общими рекомендациями.
Основной слабой стороной Erlang является обработка данных, в частности:
- Текстовые строки в Erlang реализованы как однонаправленный связанный список целых чисел, то есть на каждый символ выделяется восемь байт памяти: четыре на код символа, четыре - на указатель на следующий символ; плюс еще четыре байта для указателя на начало списка. Для 64-битных систем эти цифры нужно удвоить, так как машинное слово вдвое длиннее. Помимо неоправданных расходов памяти, эта схема усложняет различные операции со строками, например чтобы посчитать длину строки нужно "пройтись" по ней целиком. А чтобы приписать один символ в конец строки, нужно сделать её полную копию (для записи в начало это не так, как не трудно догадаться).
- Бинарные строки хранятся в памяти последовательно, так что объем не удваивается из-за указателей. Изменения в итоге также создают копии данных, что для больших строк накладно. В любом случае там где это возможно я бы рекомендовал использовать бинарные строки вместо текстовых.
- С математическими задачами все не так плачевно: хоть и реализация базовых операций в виртуальной машине несколько отстает по производительности от чистого С, при желании его можно практически догнать средствами нативной компиляции, грамотной реализации алгоритма и отсутствия "палок в колесах" у компилятора. Альтернативный сценарий: использование NIF.
Для не-англоязычных проектов трудностью может оказаться довольно сомнительная поддержка Unicode: особого типа данных нет, в тех же текстовых строках код символа может выходить за пределы таблицы ASCII (не зря же на него 32 или 64 бита выделили), а в бинарных строках можно хранить что угодно, в т.ч. и Unicode-текст. Как прореагирует на Unicode тот или иной встроенный модуль или используемая библиотека никто не гарантирует, но обычно все более-менее нормально.
Хоть на самом деле это и является роскошью, но при реализации бизнес-логики на Erlang порой недостает ORM-подобных механизмов в духе "вытащил объект из базы, поменял в нем что-нибудь, положил обратно". Не то чтобы таких библиотек нет, просто эта схема не очень хорошо "ложится" на функциональную парадигму и реализуется обычно через не особо предназначенные для этого механизмы словарей (dict) или именованных кортежей (record).
В качестве резюме хочется сказать, что на Erlang можно реализовать бизнес-логику практически любого интернет-проекта. Просто если она сложнее, чем просто передать какие-то данные от одного пользователя другому, то вероятно из-за искусственных ограничений и недостаточной выразительности языка для эффективной её разработки на Erlang может потребоваться существенно больше времени и усилий, чем на более приспособленных для этого языках вроде Ruby, PHP и Python.
Базы данных
Здесь все довольно просто: обычно Erlang используется как распределенная надстройка над встраиваемыми СУБД или особыми форматами файлов. Основные представители: Riak (Google LevelDB), CouchDB (свой формат), Mnesia (DETS), Couchbase (memcached и SQLite) - все совершенно разные, обсуждать и сравнивать можно до бесконечности, так что оставим это на другой раз.
Из общих особенностей вышеперечисленных решений можно выделить:
- Прозрачная горизонтальная масштабируемость;
- Настраиваемый уровень репликации данных;
- Обычно доступность и персистентность в ущерб строгой целостности (AP из CAP-теоремы);
- Поддержка сложных распределенных выборок (MapReduce, многокритериальная фильтрация, полнотекстный поиск и т.п., за исключением Couchbase)
- Способность легко справляться с большим потоком изменений данных (за исключением, пожалуй, CouchDB);
- Отсутствие строгой схемы данных и SQL-подобного интерфейса.
Подводим итоги
Erlang в умелых руках может послужить и правда удачным решением для реализации многих аспектов интернет-проектов, благодаря качественной, проверенной временем, основе в виде виртуальной машины и OTP, а также продуманной модели легковесных процессов. В результате получаются высокопроизводительные, горизонтально масштабируемые приложения, полностью приспособленные для стабильной бесперебойной работы в боевых условиях.
Высокий барьер обучения специалистов по-прежнему остается весомым аргументом "против", но если в проекте команда разработчиков уровня выше среднего - вряд ли это станет серьезным препятствием. Недостаток "готовых" квалифицированных специалистов по Erlang на трудовом рынке также не особо радует, но ситуация определенно постепенно улучшается.
В комментариях предлагаю обсудить по каким еще причинам на сегодняшний день Erlang столь редко можно увидеть в технологическом стеке интернет-проектов? Какие еще вопросы смущают руководство и разработчиков? В каких ситуациях преодоление сложностей и ограничений, связанных с Erlang, того стоит?
Эта статья определенно будет далеко не последней про Erlang, так что если эта тема Вам близка - рекомендую подписаться на RSS.